These pages are not displaying properly because the Compatibility View in your Internet Explorer is enabled. We suggest that you remove 'fu-berlin.de' from your list of sites that have Compatibility View enabled.
- In Internet Explorer, press the 'Alt' key to display the Menu bar, or press and hold the address bar and select 'Menu bar'.
- Click 'Tools' and select 'Compatibility View settings'.
- Select 'fu-berlin.de' under 'Websites you've added to Compatibility View'.
- Click 'Remove'.
Support Vector Machine (Statistics)
The master bioinformatics offers the chance to get acquainted to several machine learning techniques. Machine learning algorithms are used in various courses, the theoretical ground work is taught in statistics. There we repeat how linear regression and hidden markov machines work, learning more about the mathematical concept of markov chains, and we get introduced to support vector machines (SVMs) and how to make them more efficient using the kernel trick.
SVMs are supervised learning models usually used on very large data sets which you want to divide into two classes. The division is performed by laying a plane or hyperplane between the two classes and maximizing the distance to each of them. If the classes are not linearly separable you have to transform the input space with a transformation function, called phi here, which introduces more dimensions. This function phi has to be cleverly chosen such that the two classes get cleanly separated without introducing too many new dimensions. Of course if you add enough dimensions everything can become separable, even if in reality there are no features distinguishing them. Another problem with adding too many dimensions is overfitting (learning properties of single data points instead of general class properties). Even when it does make sense to introduce this many new dimensions you will end up running into the curse of dimensionality. For with every new dimension the input points end up further apart from each other until the data is so sparse that the positioning of the dividing hyper plane becomes in a way arbitrary, which of course compromises your results when trying to classify new points.
Match the functions used for transforming the input space to the resulting decision borders. x=(x1,x2)
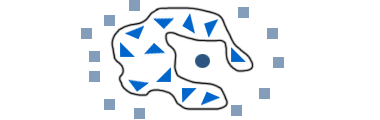
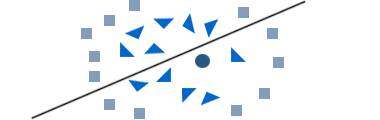
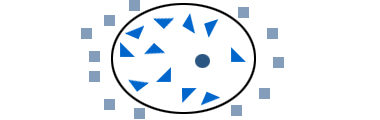
Imagine that the points represent patients with a certain disease which we want to classify by measuring certain biomarkers. Squares indicate healthy patients, triangles diseased patiens. Now we want to predict if the patient marked with the circle is sick.
Mark if the following statements are true or not.
The new patient can be classified correctly with a model like model 1.
It can happen but it would be due to chance, not due to a good model.
Model 1 shouldn't be trusted because of the curse of dimensionality.
We didn't change the number of dimensions yet.
We should use the most simple model which still explains the data correctly.
That is generally what we do in science (see Ockham's razor).
Raising the number of dimension above 50 will never give good results.
In most problems this would be overkill, but if you have a lot of explaining features and a huge amount of data available it might be necessary and doable.
You get feedback for each answer by clicking on the button.